AI/ML Products
Octolynx
July 2025- Present
I am building Octolynx, an AI-driven talent intelligence platform targeting the $18B predictive talent assessment market. Octolynx helps hiring professionals and talent acquisition teams evaluate candidate pools across three critical dimensions: Team Collaboration, Business Acumen, and Domain Expertise (including AI readiness). Using proprietary logic and custom datasets, the platform dynamically adjusts scoring weightages and difficulty levels for each dimension, generates highly contextualized job architectures, and maps them to advanced situational assessment modules. My objective is to eliminate systemic hiring biases from both the employer and candidate perspectives by scoring individuals purely on their problem-identification and execution capabilities under diverse situational settings.
The platform's primary impact metrics focus on optimizing user experience—aiming for high candidate satisfaction scores and a significantly reduced Time-to-Hire (TTH)—while delivering maximum, measurable recruitment ROI across both short- and long-term hiring intervals.

Project Traction & Status
Current Stage: Beta (Target Launch: July 2026)
Intellectual Property: 2 Provisional Patents Filed (Core Orchestration & Evaluation Architecture)
Target Segment: SAAS Startups and Enterprise with requirement of highly disruptive roles
Core Technical Stack: LangGraph (Stateful Orchestration), FastAPI, Pydantic, Various LLM Model
SynthResume: Portfolio-to-Resume via Deterministic RAG Synthesis
March 2026- Present
ATS-optimized, reproducible outputs backed by your actual portfolio content.


How It Works
1. Scrape your portfolio website to capture your actual experience
2. Match against job description via RAG vector similarity
3. Synthesize tailored, ATS-optimized resume and cover letter PDFs
Why Deterministic Matters
Every output is reproducible and backed by your real portfolio content. Same portfolio + same job description = consistent results across runs. Perfect for competitive job hunting where reliability counts.
Built with Google Gemini, FAISS vector embeddings, and portfolio scraping—no hallucinations, no fluff. Just tailored application materials grounded in your actual work.
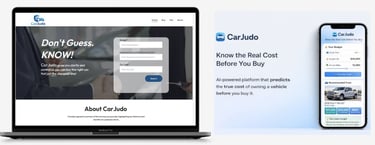
CarJudo: The Intelligence Layer for Automotive Assets
Jan 2026- Present
CarJudo is an AI-driven "Decision Intelligence" engine designed to de-risk the $1 Trillion U.S. used car market. While traditional aggregators focus on inventory and historical logs, CarJudo operates as a buy-side fiduciary, transforming fragmented data into predictive risk profiles. By narrowing a user's choice to the most mechanically sound and financially viable models, it generates high-intent, mature leads for the broader automotive ecosystem.
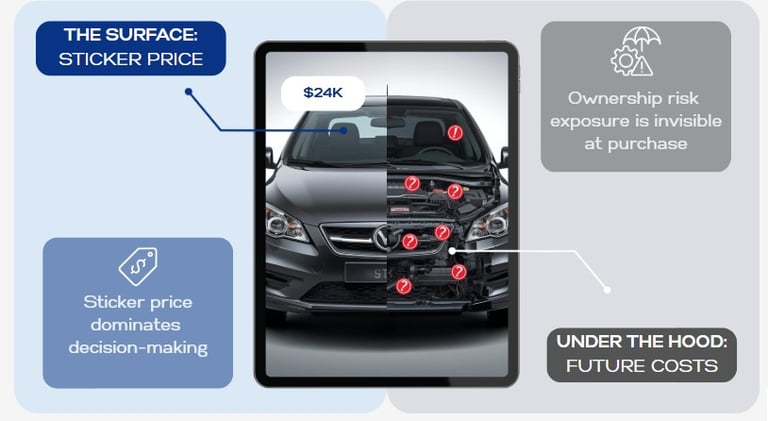
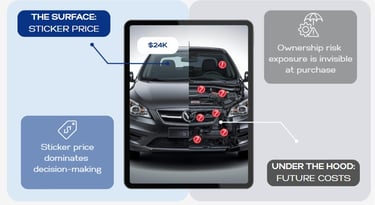
Metric Value Delivered
Hidden Liability Gap Converts vague mechanical anxiety into a quantified financial signal by identifying an average of $3,000–$5,000 in unpriced annual maintenance exposure.
Lead Maturity Rate Increases conversion for partners by delivering customers who have already cleared the 15-hour "Synthesis Burden" and are ready to transact.
Research Velocity Replaces fragmented manual searches with a 60-second 1–100 Confidence Score, accelerating the decision-to-purchase timeline.
Predictive Cost Transparency Provides a forward-looking view of ownership, ensuring that the annual cost of upkeep is factored into the initial purchase decision.
Data Model: BabsonAI Labs Operational Data Architecture
Sept- Dec 2025
Objective: Designed and implemented a relational database for a budding AI start-up to eliminate data silos, prevent redundant entries, and enable automated operational reporting.
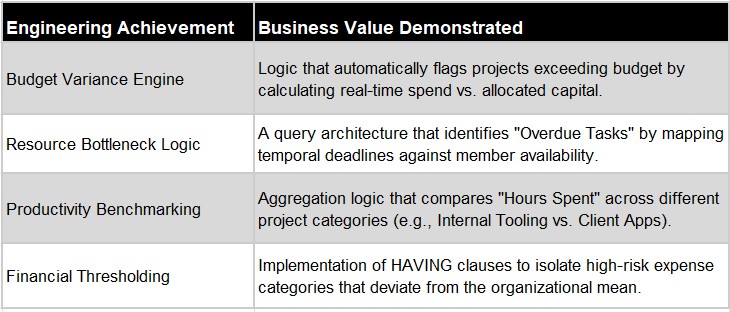
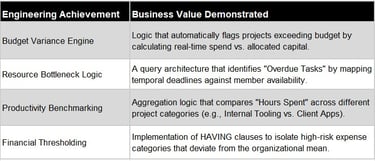
Data Modeling: Developed a comprehensive Entity-Relationship Diagram (ERD) covering 7 core entities (Members, Projects, Clients, Tasks, Trackers, and Expenses) with defined cardinalities and referential integrity (Cascading/Non-Cascading).
Technical Implementation: Normalized and migrated mock datasets (100+ task entries, 500+ expense records) into DBeaver using SQL.
Business Intelligence: Authored complex SQL queries (Joins, Aggregations, Window Functions, and CASE statements) to transform raw operational data into actionable management insights.
Machine Learning Model: Credit Risk & Financial Distress Prediction
Jan- May 2025
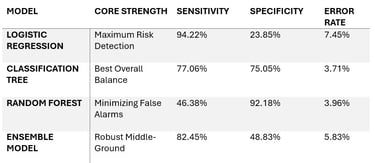
Objective: Developed a predictive framework to identify at-risk borrowers likely to experience a financial crisis within two years, specifically aiming to balance high sensitivity (detecting defaults) with high specificity (minimizing false alarms for stable customers).
Data Engineering & Preprocessing
Dataset: 150,000 observations with 12 variables (e.g., Debt Ratio, Monthly Income, Credit Utilization).
Handling Missing Data: Used Predictive Imputation for 30,000 rows (Monthly Income and Dependents) to preserve data integrity over simple mean/mode substitution.
Feature Selection: Conducted correlation analysis to remove near-perfectly correlated variables (0.98–0.99), mitigating multicollinearity.
Class Imbalance Strategy: Addressed a severe 90/10 class split using Inverse Frequency Weighting, which amplified the influence of the minority "defaulter" class during training.